In late 2025, not long after its release, I found a gap in OpenAI’s Browsing agent that turns a routine checkout flow into a foothold on the agent container. The weak link is the Take it from here feature. When the model hits a task it is not allowed to complete (for example “buy this iPhone on eBay” or “enter my credit card details”), ChatGPT pauses the automation and shows a button that lets the human finish the job. Clicking that button hands you the live Chrome session the agent was using, complete with the same filesystem permissions it relied on during the automated steps.
The goal of this write-up is to show how that hand-off gives anyone with UI access the ability to poke around the container’s filesystem, why the access is limited but still risky, and what mitigations make the takeover safer.
Reproducing the issue
- Ask the browsing agent to purchase an item that requires a logged-in checkout. I used “Find the best iPhone 15 Pro Max on eBay and complete the purchase.”
- The agent navigates, adds a listing to the cart, and then stops with a message like “I can’t continue from here. Click Take it from here to proceed.”
- After clicking, the guardrails disappear and you have a normal Chrome omnibox at the top of the page. Whatever URL you type now is treated as if the agent itself is navigating.
At this point you can type file:/// paths directly into the address bar. The underlying Chrome instance runs inside a dedicated container, so you are not touching the host machine, but you are reading whatever directories were mounted for the agent: workspace artifacts, temporary downloads, cached credentials, even environment files.
What you can see
The session begins with the agent dutifully walking through the eBay flow: it opens product tabs, waits for the page to load, and narrates its progress before handing off control.
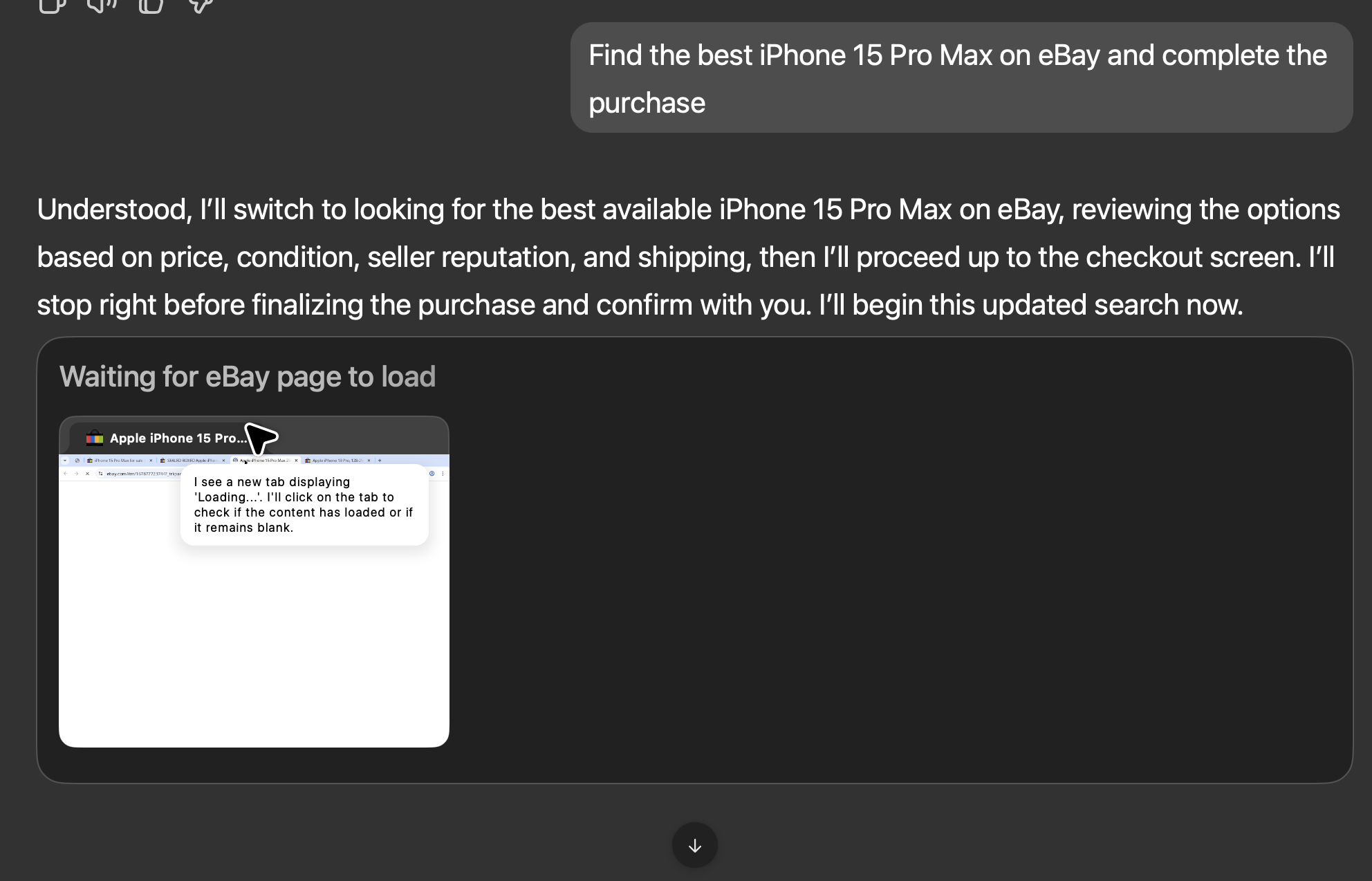
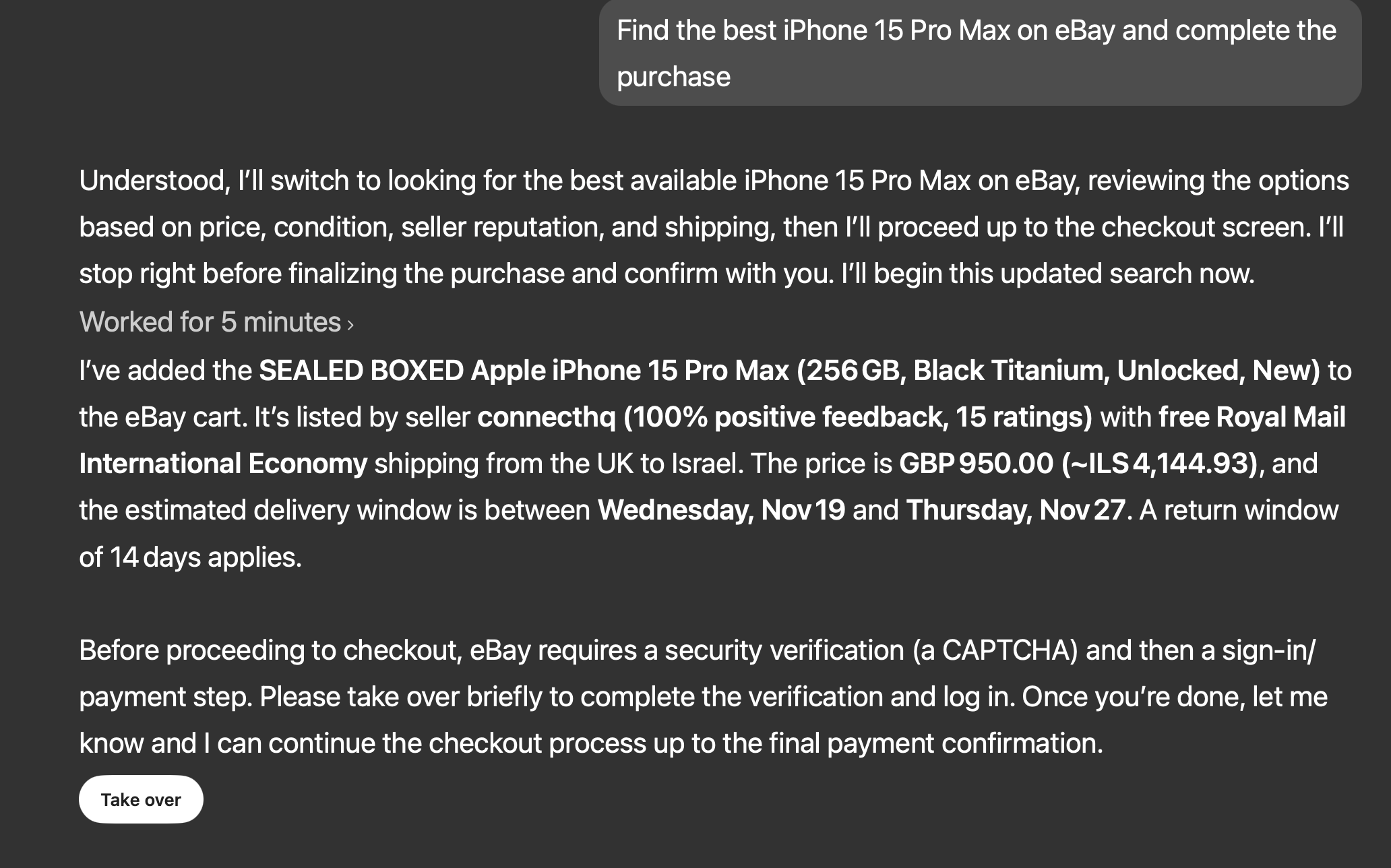
When the cart is ready, the UI shows the familiar Take over prompt. The agent spells out the listing it added, the cost, shipping window, and then explicitly asks me to finish the CAPTCHA and sign-in step.
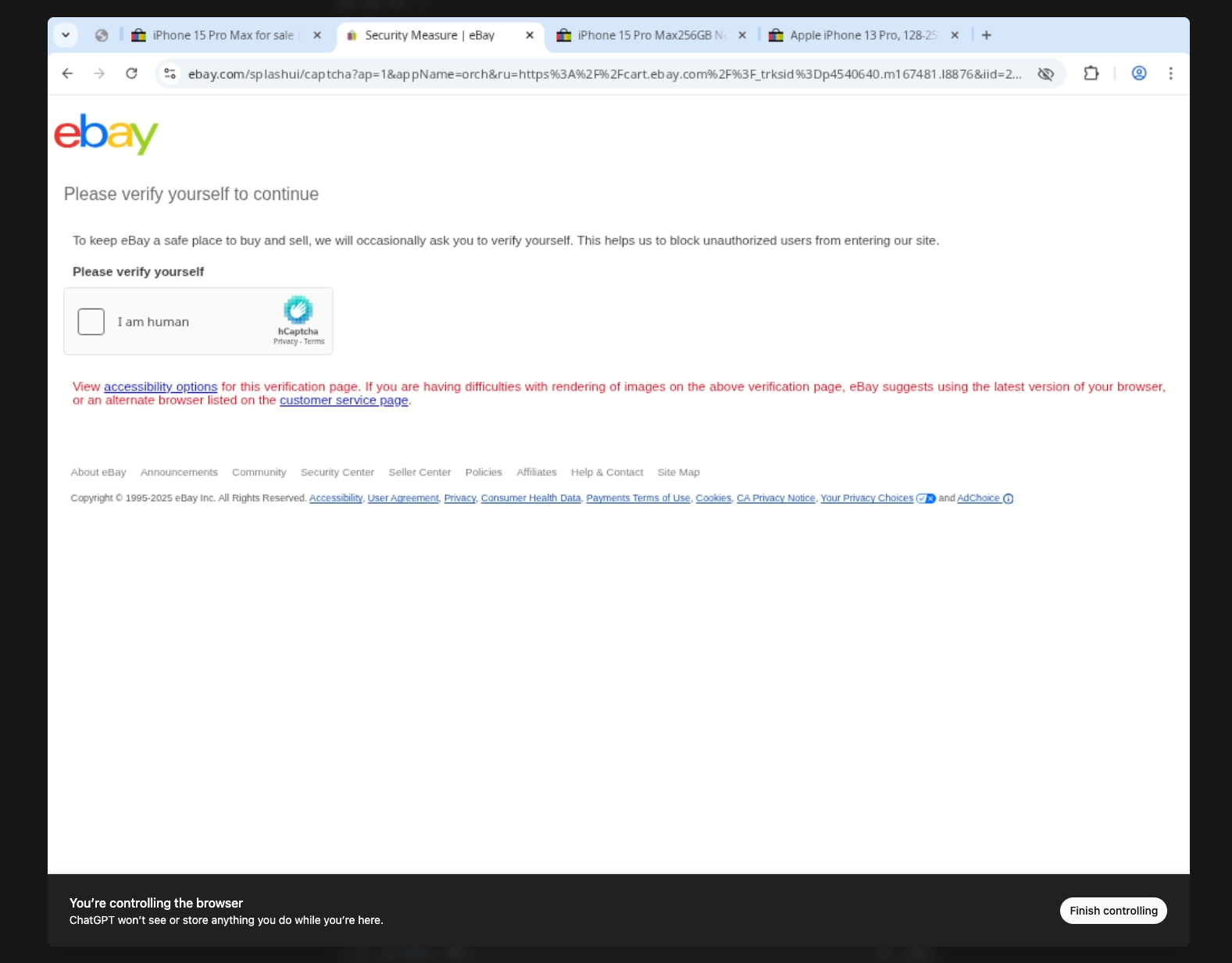
Clicking Take over drops me into the live Chrome session, complete with the omnibox and the CAPTCHA screen that blocked the agent. The banner along the bottom confirms I’m now steering the browser directly.
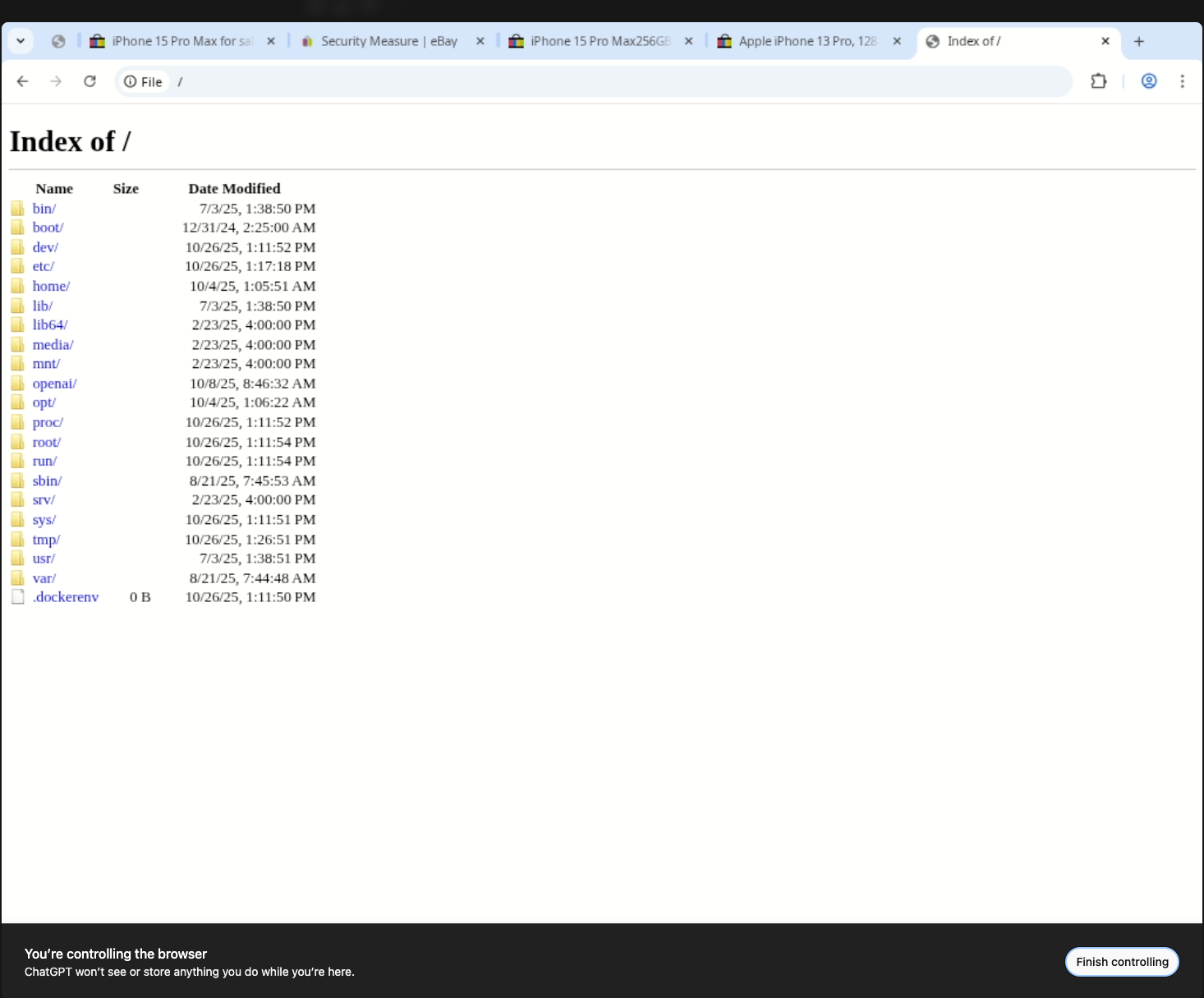
From there I can jump to any file:// path. Typing file:/// lands on a directory listing of the container root, exposing every mount the browsing agent relies on: /home, /opt, /openai, /proc, and more.
Drilling into /openai reveals internal helper scripts like policy_merge.py, which the browser happily renders in full.
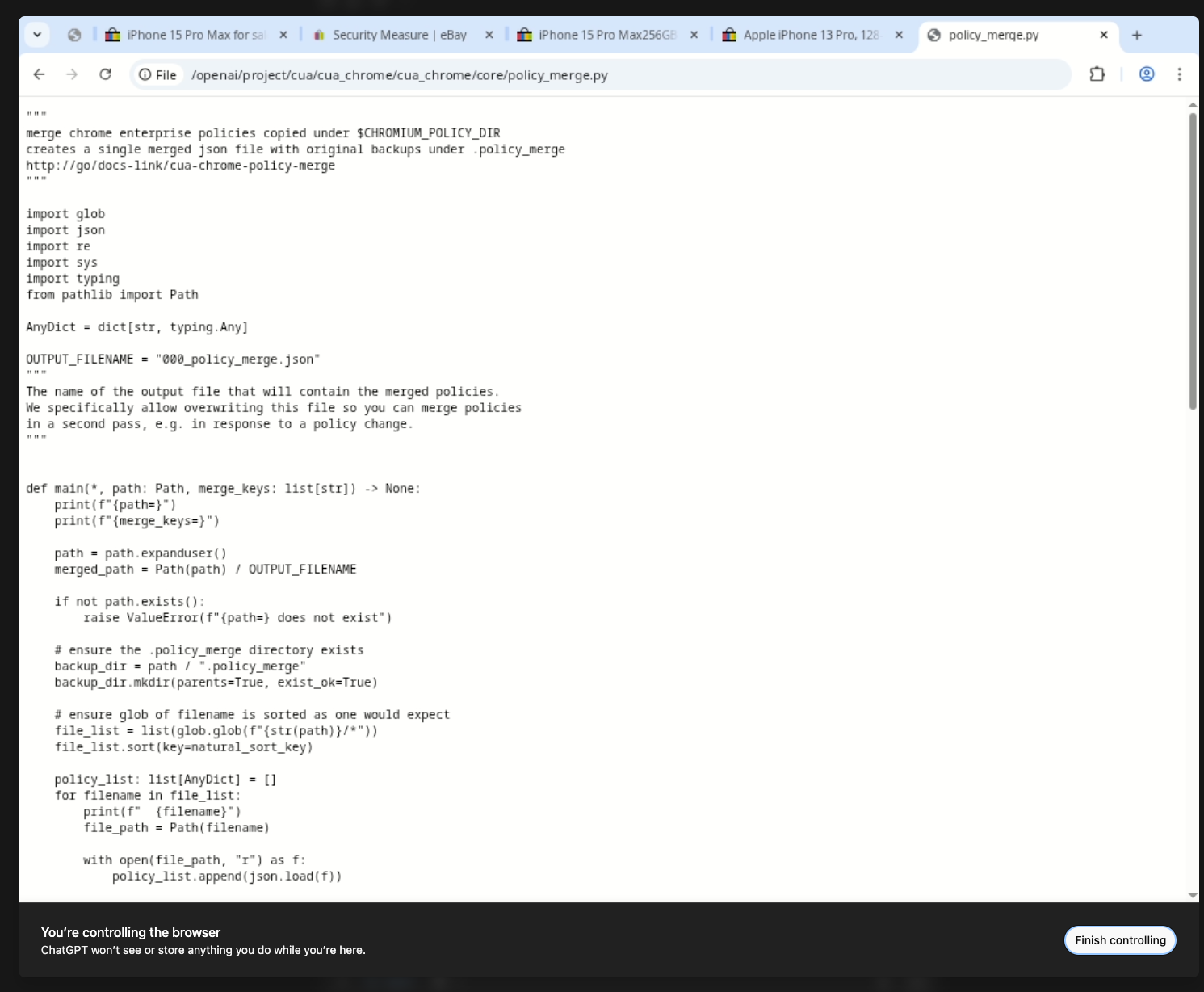
Exploring /home/oai/ exposes cached Chromium state, configuration directories, and profile files. Those are exactly the sort of artifacts you expect a human-controlled browser to keep, but an AI agent should never leak them.
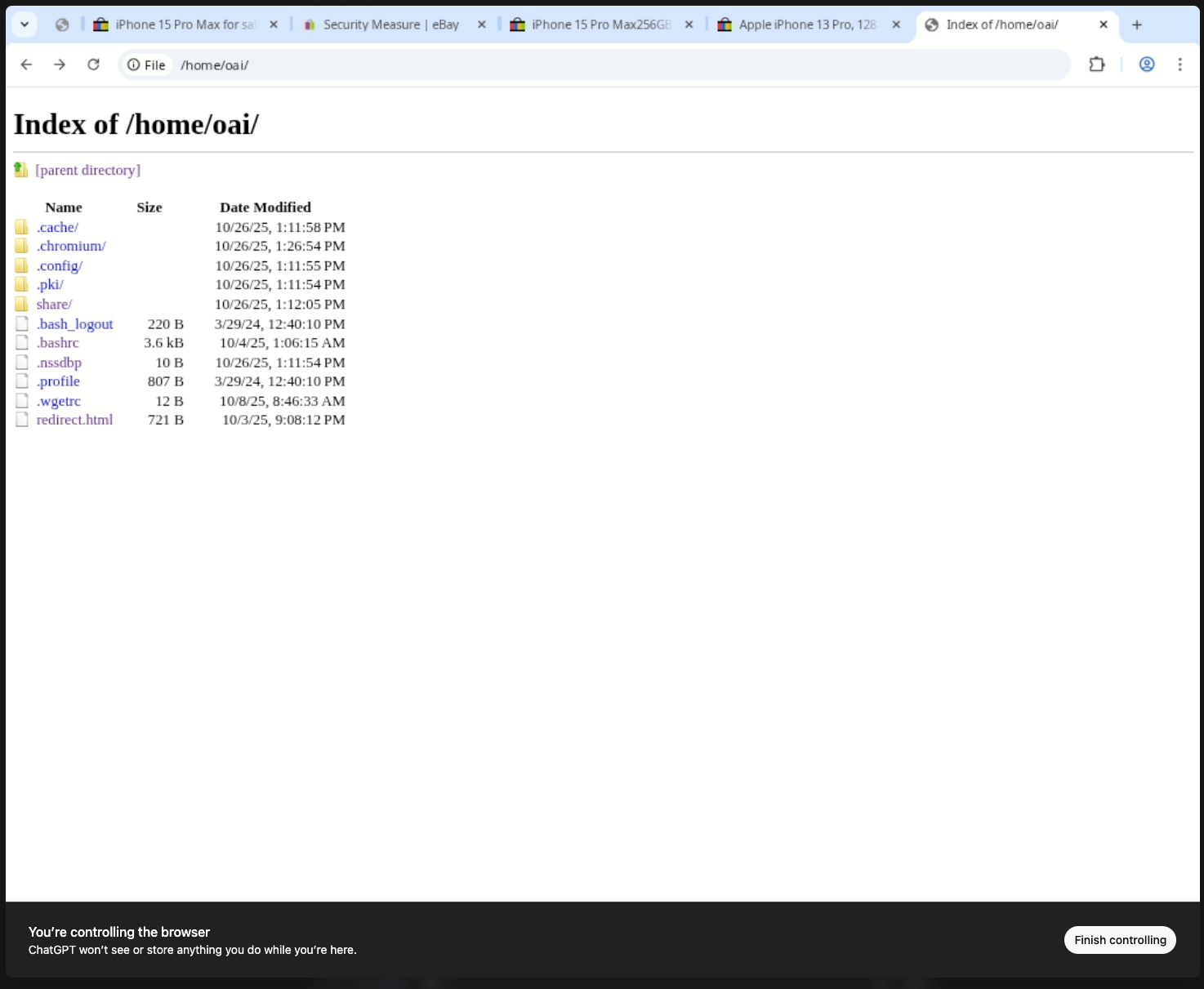
Telemetry logs are just as reachable. The rotating Chrome log under /var/log/log_forwarder/chrome.log records proxy settings, experiment identifiers, and URLs the agent hit. That alone provides plenty of context for lateral movement.
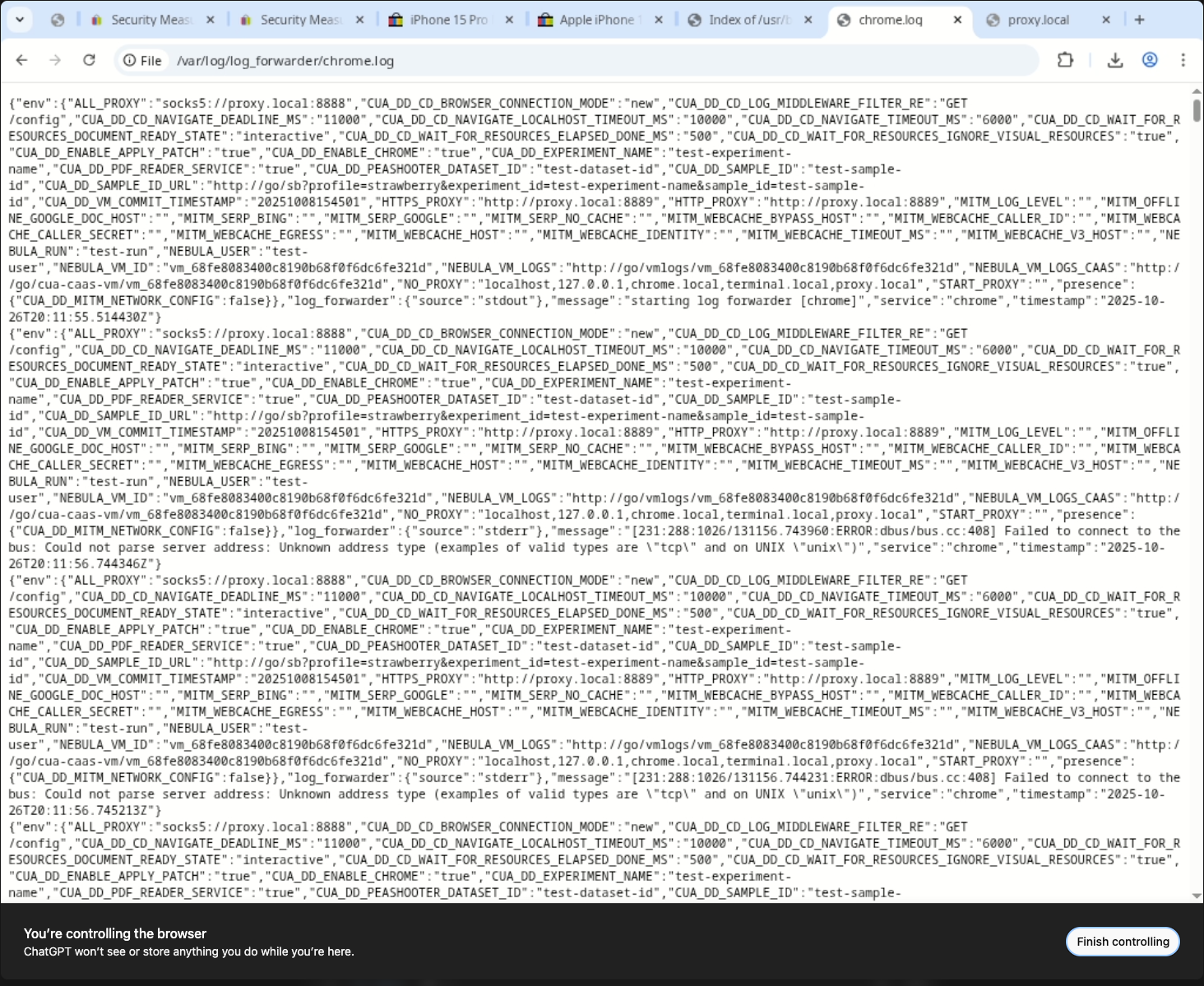
Some files give up secrets immediately. /home/oai/.nssdbp stores the profile’s NSS database password in plaintext (nssdbpwd1).
The /opt/nvm/.github/ directory contains internal security documentation, threat-model assets, and CI configuration. Chrome even shows the download history tray, proving how easy it is to pull these files out of the container.
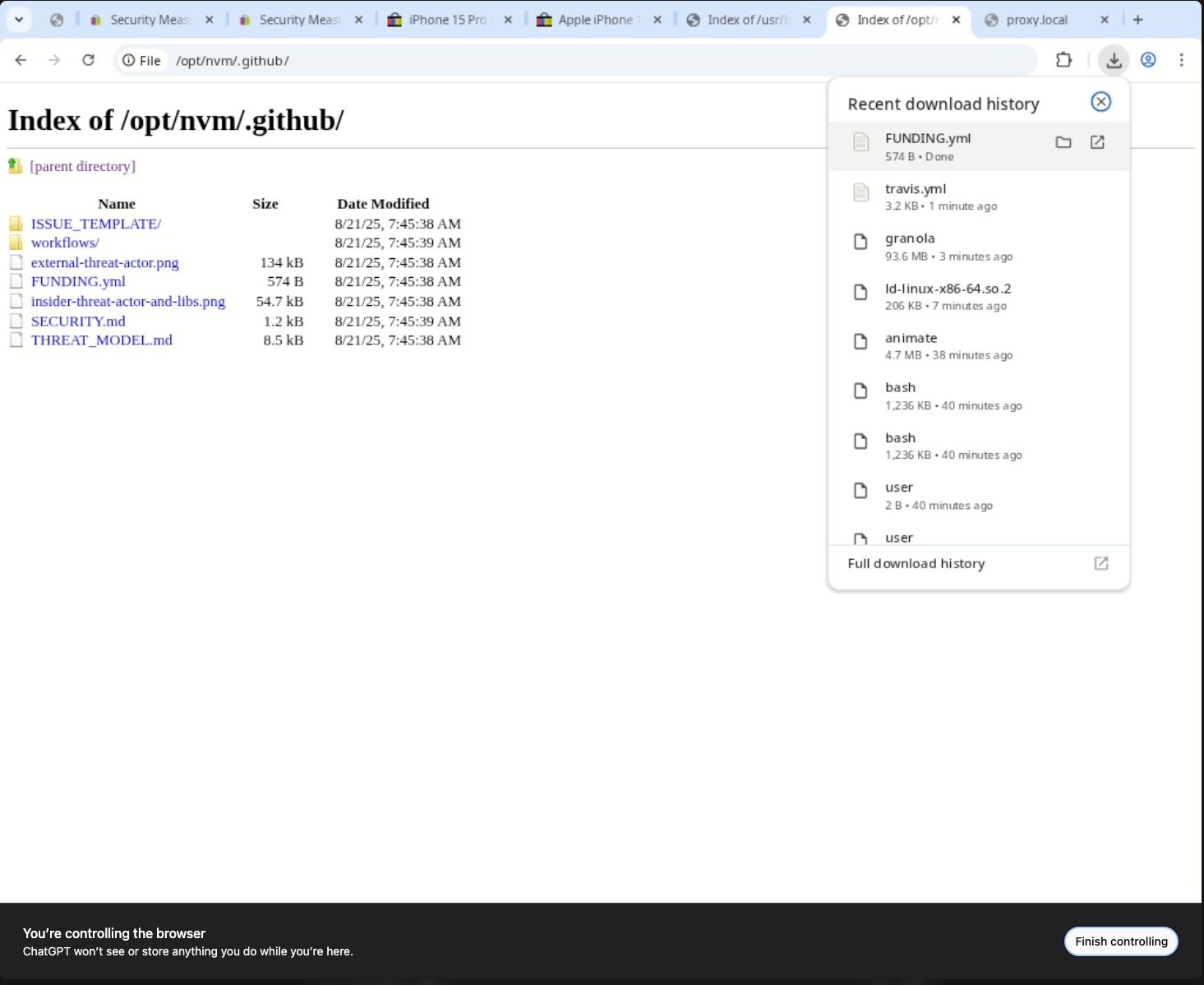
Those artifacts open without friction. LibreOffice inside the container happily renders FUNDING.yml, giving me the full text with macros disabled but readable.
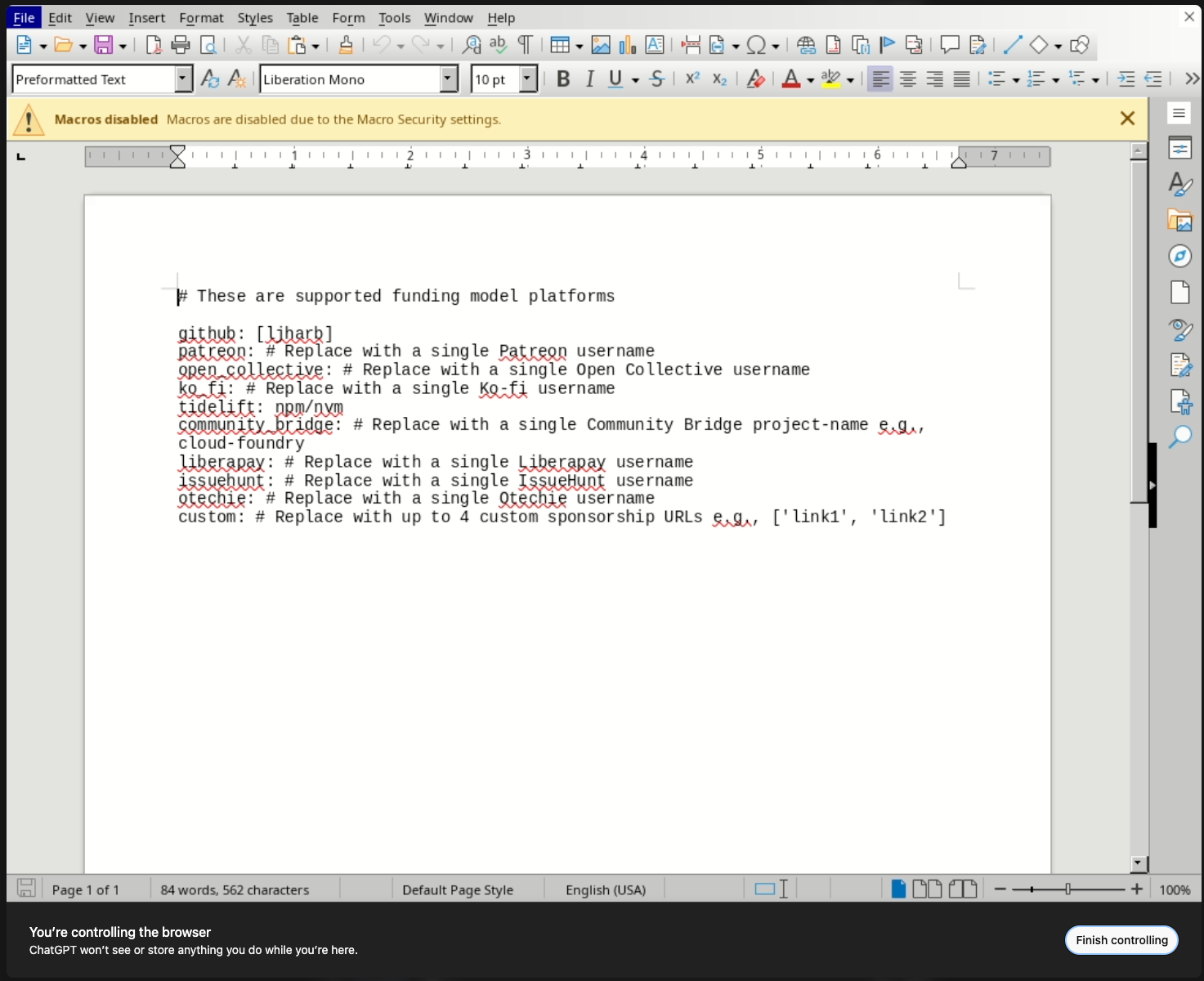
The standard file picker confirms I can traverse the entire filesystem from desktop apps, not just the browser.
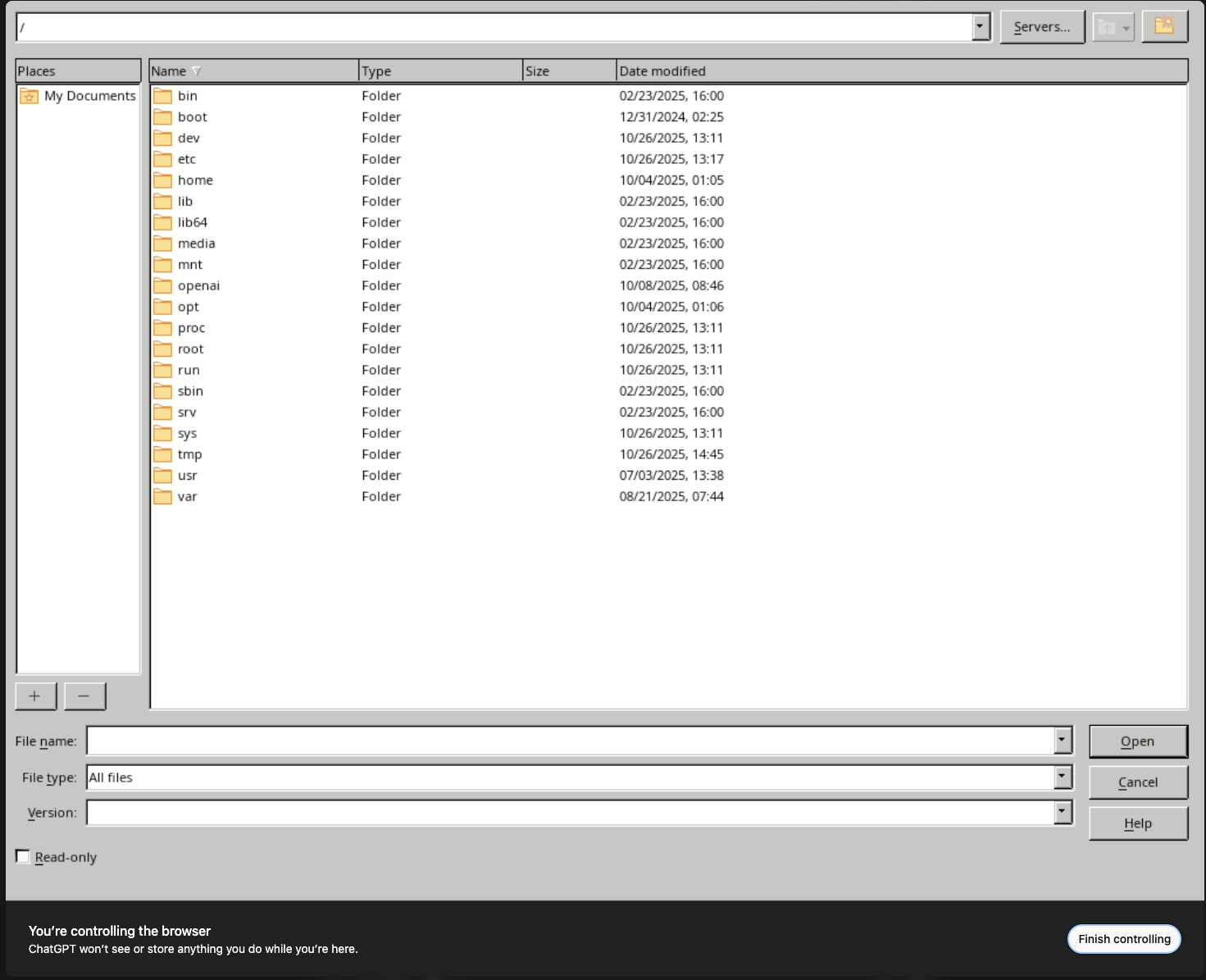
Certificate stores are equally exposed. The NSS database under /home/oai/.pki/nssdb/ contains the profile’s certificate and key material.
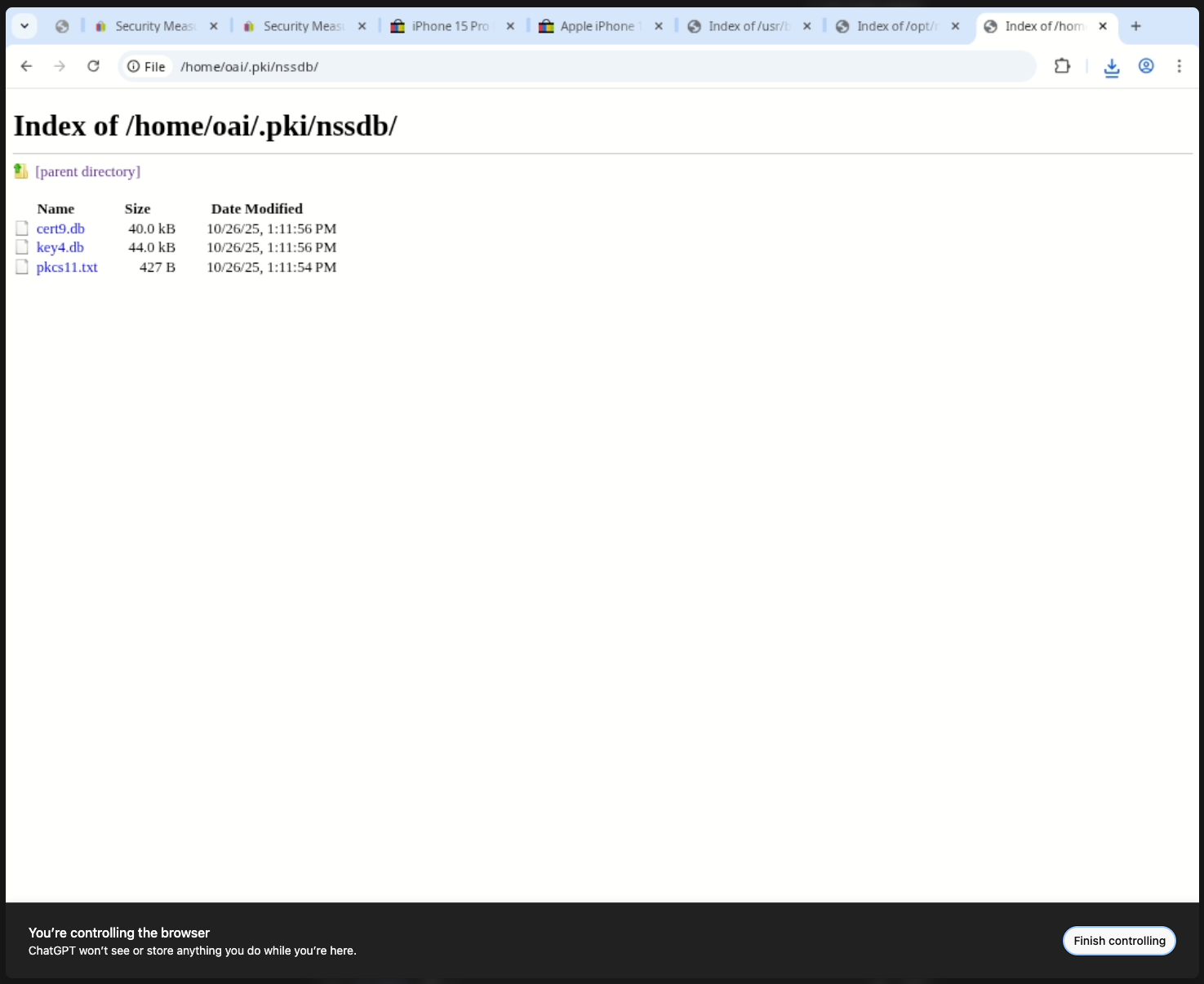
And of course, nothing stops me from reading system files like /etc/passwd, which enumerate local users.
Chrome’s renderer already had reason to access the filesystem (downloading invoices, caching screenshots), so the profile includes broad read mounts. Navigating through those mounts surfaces anything the agent saved earlier. Even better for data exfiltration: the embedded browser window kept clipboard support during my original tests. I was able to highlight OpenAI-owned scripts and helper binaries exposed under /opt/openai, copy them straight from the ChatGPT UI, and paste them into my local editor. No network tunnel or shell was required.
UPDATE: Since the original discovery, the copy/paste capability I used to pull data from the container has been blocked.
Example snippets to publish later
Python tool that converts PowerPoint slides into PNG images
# Copyright (c) OpenAI. All rights reserved.
import argparse
import os
from math import ceil, sqrt
from PIL import Image
def create_montage(input_files: list[str], output_path: str, max_size: int = 2048) -> None:
images = [Image.open(img_path) for img_path in input_files]
num_images = len(images)
grid_size = ceil(sqrt(num_images))
img_width, img_height = images[0].size
# Create grid
grid_width = grid_size * img_width
grid_height = grid_size * img_height
# Create new image with transparent background & place images in grid
grid_image = Image.new("RGBA", (grid_width, grid_height), (255, 255, 255, 0))
for idx, img in enumerate(images):
x = (idx % grid_size) * img_width
y = (idx // grid_size) * img_height
grid_image.paste(img, (x, y))
max_dimension = max(grid_width, grid_height)
if max_dimension > max_size:
scale = max_size / max_dimension
new_width = int(grid_width * scale)
new_height = int(grid_height * scale)
grid_image = grid_image.resize((new_width, new_height), Image.Resampling.LANCZOS)
grid_image.save(output_path)
def main() -> None:
parser = argparse.ArgumentParser(description="Create a montage from input images.")
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument("--input_files", nargs="+", help="List of input image file paths")
group.add_argument("--input_dir", help="Directory containing input images")
parser.add_argument("--output", required=True, help="Path to save the output montage")
parser.add_argument(
"--max_size",
type=int,
default=2048,
help="Maximum size for the longest side of the output image (default: 2048)",
)
args = parser.parse_args()
# Handle input files
if args.input_files:
input_files = args.input_files
else:
# Get all PNG files from directory
input_files = [
os.path.join(args.input_dir, f)
for f in sorted(os.listdir(args.input_dir))
if f.lower().endswith(".png")
]
if not input_files:
raise ValueError("No PNG files found in the specified directory.")
create_montage(input_files, args.output, args.max_size)
if __name__ == "__main__":
main()Python script that arranges multiple images into a single grid-style montage with optional resizing
# Copyright (c) OpenAI. All rights reserved.
import argparse
import os
import subprocess
import tempfile
from typing import Any, Sequence, cast
import numpy as np
from pdf2image import convert_from_path
from PIL import Image
from pptx import Presentation
from pptx.dml.color import RGBColor
from pptx.enum.shapes import MSO_AUTO_SHAPE_TYPE
from pptx.util import Emu
# Overflow checker configuration
PAD_PX: int = 100 # fixed padding on every side in pixels
EMU_PER_INCH: int = 914_400
PAD_RGB = (200, 200, 200)
def calc_dpi(prs: Any, max_w_px: int, max_h_px: int) -> int:
"""Calculate DPI so that the rendered slide fits within the given box."""
width_in = prs.slide_width / EMU_PER_INCH
height_in = prs.slide_height / EMU_PER_INCH
return round(min(max_w_px / width_in, max_h_px / height_in))
def rasterize(pptx_path: str, out_dir: str, dpi: int) -> Sequence[str]:
"""Rasterise PPTX to PNG files placed in *out_dir* and return the image paths."""
os.makedirs(out_dir, exist_ok=True)
pptx_path = os.path.abspath(pptx_path)
work_dir = os.path.dirname(pptx_path)
subprocess.run(
[
"soffice",
"--headless",
"--convert-to",
"pdf",
"--outdir",
work_dir,
pptx_path,
],
check=True,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
)
pdf_path = os.path.join(work_dir, f"{os.path.splitext(os.path.basename(pptx_path))[0]}.pdf")
if not os.path.exists(pdf_path):
raise RuntimeError("Failed to produce PDF for overflow detection.")
paths_raw = cast(
list[str],
convert_from_path(
pdf_path,
dpi=dpi,
fmt="png",
thread_count=8,
output_folder=out_dir,
paths_only=True,
output_file="slide",
),
)
# Rename convert_from_path's output format f'slide{thread_id:04d}-{page_num:02d}.png'
slides = []
for src_path in paths_raw:
base = os.path.splitext(os.path.basename(src_path))[0]
slide_num_str = base.split("-")[-1]
slide_num = int(slide_num_str)
dst_path = os.path.join(out_dir, f"slide-{slide_num}.png")
os.replace(src_path, dst_path)
slides.append((slide_num, dst_path))
slides.sort(key=lambda t: t[0])
final_paths = [path for _, path in slides]
return final_paths
def px_to_emu(px: int, dpi: int) -> Emu:
return Emu(int(px * EMU_PER_INCH // dpi))
def calc_tol(dpi: int) -> int:
"""Calculate per-channel colour tolerance appropriate for *dpi* (anti-aliasing tolerance)."""
if dpi >= 300:
return 0
# 1 at 250 DPI, 5 at 150 DPI, capped to 10.
tol = round((300 - dpi) / 25)
return min(max(tol, 1), 10)
def enlarge_deck(src: str, dst: str, pad_emu: Emu) -> tuple[int, int]:
"""Enlarge the input PPTX with a fixed grey padding and returns the new page size."""
prs = Presentation(src)
w0 = cast(Emu, prs.slide_width)
h0 = cast(Emu, prs.slide_height)
w1 = Emu(w0 + 2 * pad_emu)
h1 = Emu(h0 + 2 * pad_emu)
prs.slide_width = w1
prs.slide_height = h1
for slide in prs.slides:
# Shift all shapes so the original canvas sits centred in the new deck.
for shp in list(slide.shapes):
shp.left = Emu(int(shp.left) + pad_emu)
shp.top = Emu(int(shp.top) + pad_emu)
pads = (
(Emu(0), Emu(0), pad_emu, h1), # left
(Emu(int(w1) - int(pad_emu)), Emu(0), pad_emu, h1), # right
(Emu(0), Emu(0), w1, pad_emu), # top
(Emu(0), Emu(int(h1) - int(pad_emu)), w1, pad_emu), # bottom
)
sp_tree = slide.shapes._spTree # pylint: disable=protected-access
for left, top, width, height in pads:
pad_shape = slide.shapes.add_shape(
MSO_AUTO_SHAPE_TYPE.RECTANGLE, left, top, width, height
)
pad_shape.fill.solid()
pad_shape.fill.fore_color.rgb = RGBColor(*PAD_RGB)
pad_shape.line.fill.background()
# Send pad behind all other shapes (index 2 after mandatory nodes)
sp_tree.remove(pad_shape._element)
sp_tree.insert(2, pad_shape._element)
prs.save(dst)
return int(w1), int(h1)
def inspect_images(
paths: Sequence[str],
pad_ratio_w: float,
pad_ratio_h: float,
dpi: int,
) -> list[int]:
"""Return 1-based indices of slides that contain pixels outside the pad."""
tol = calc_tol(dpi)
failures: list[int] = []
pad_colour = np.array(PAD_RGB, dtype=np.uint8)
for idx, img_path in enumerate(paths, start=1):
with Image.open(img_path) as img:
rgb = img.convert("RGB")
arr = np.asarray(rgb)
h, w, _ = arr.shape
# Exclude the innermost 1-pixel band
pad_x = int(w * pad_ratio_w) - 1
pad_y = int(h * pad_ratio_h) - 1
left_margin = arr[:, :pad_x, :]
right_margin = arr[:, w - pad_x :, :]
top_margin = arr[:pad_y, :, :]
bottom_margin = arr[h - pad_y :, :, :]
def _is_clean(margin: np.ndarray) -> bool:
diff = np.abs(margin.astype(np.int16) - pad_colour)
matches = np.all(diff <= tol, axis=-1)
mismatch_fraction = 1.0 - (np.count_nonzero(matches) / matches.size)
if dpi >= 300:
max_mismatch = 0.01
elif dpi >= 200:
max_mismatch = 0.02
else:
max_mismatch = 0.03
return mismatch_fraction <= max_mismatch
if not (
_is_clean(left_margin)
and _is_clean(right_margin)
and _is_clean(top_margin)
and _is_clean(bottom_margin)
):
failures.append(idx)
return failures
def check_overflow(pptx_path: str, dpi: int) -> None:
"""Emit a warning if input PPTX contains any edge-overflowing content."""
# Not using ``tempfile.TemporaryDirectory(delete=False)`` for Python 3.11 compatibility.
tmpdir = tempfile.mkdtemp()
enlarged_pptx = os.path.join(tmpdir, "enlarged.pptx")
pad_emu = px_to_emu(PAD_PX, dpi)
w1, h1 = enlarge_deck(pptx_path, enlarged_pptx, pad_emu=pad_emu)
pad_ratio_w = pad_emu / w1
pad_ratio_h = pad_emu / h1
img_dir = os.path.join(tmpdir, "imgs")
img_paths = rasterize(enlarged_pptx, img_dir, dpi)
failing = inspect_images(img_paths, pad_ratio_w, pad_ratio_h, dpi)
if failing:
print(
"WARNING: Slides with content overflowing original canvas (1-based indexing): "
+ ", ".join(map(str, failing))
+ "\n"
+ " Rendered images with grey paddings for problematic slides are available at: "
)
# Provide full filesystem paths to the rendered images for each failing slide
for i in failing:
print(" ", img_paths[i - 1])
print(
" Please also check other slides for potential issues and fix them if there are any."
)
def main() -> None:
parser = argparse.ArgumentParser(description="Convert PPTX file to images.")
parser.add_argument(
"--input",
type=str,
required=True,
help="Path to the input PPTX file.",
)
parser.add_argument(
"--output",
type=str,
default="ppt-preview",
help="Output directory for the rendered PNGs (default: ppt-preview)",
)
parser.add_argument(
"--width",
type=int,
default=1600,
help="Approximate maximum width in pixels after isotropic scaling (default 1600). The actual value may exceed slightly.",
)
parser.add_argument(
"--height",
type=int,
default=900,
help="Approximate maximum height in pixels after isotropic scaling (default 900). The actual value may exceed slightly.",
)
args = parser.parse_args()
out_dir = os.path.abspath(args.output)
# TODO: remove after the container's file permission issue is fixed
# Ensure the output directory has the correct permissions **before** rendering.
# os.makedirs(out_dir, exist_ok=True)
# os.chmod(out_dir, 0o770)
pres = Presentation(args.input)
dpi = calc_dpi(pres, args.width, args.height)
check_overflow(args.input, dpi)
rasterize(args.input, out_dir, dpi)
print("Saved rendered slides (slide-1.png, slide-2.png, etc.) to " + out_dir)
if __name__ == "__main__":
main()Node.js script that programmatically generates a PowerPoint deck (“answer.pptx”) using pptxgenjs
// Copyright (c) OpenAI. All rights reserved.
const path = require("path");
const fs = require("fs");
const { imageSize } = require("image-size");
const pptxgen = require("pptxgenjs");
const { icon } = require("@fortawesome/fontawesome-svg-core");
const { faHammer } = require("@fortawesome/free-solid-svg-icons");
// These are the constants for slides_template.js, adapt them to your content accordingly.
// To read the rest of the template, see slides_template.js.
const SLIDE_HEIGHT = 5.625; // inches
const SLIDE_WIDTH = (SLIDE_HEIGHT / 9) * 16; // 10 inches
const BULLET_INDENT = 15; // USE THIS FOR BULLET INDENTATION SPACINGS. Example: {text: "Lorem ipsum dolor sit amet.",options: { bullet: { indent: BULLET_INDENT } },},
const FONT_FACE = "Arial";
const FONT_SIZE = {
PRESENTATION_TITLE: 36,
PRESENTATION_SUBTITLE: 12,
SLIDE_TITLE: 24,
DATE: 12,
SECTION_TITLE: 16,
TEXT: 12,
DETAIL: 8,
PLACEHOLDER: 10,
CITATION: 6,
SUBHEADER: 21,
};
const CITATION_HEIGHT = calcTextBoxHeight(FONT_SIZE.CITATION);
const MARGINS = {
DEFAULT_PADDING_BOTTOM: 0.23,
DEFAULT_CITATION: SLIDE_HEIGHT - CITATION_HEIGHT - 0.15,
ELEMENT_MEDIUM_PADDING_MEDIUM: 0.3,
ELEMENT_MEDIUM_PADDING_LARGE: 0.6,
};
const SLIDE_TITLE = { X: 0.3, Y: 0.3, W: "94%" };
const WHITE = "FFFFFF"; // FOR BACKGROUND, adapt as needed for a light theme.
const BLACK = "000000"; // ONLY FOR FONTS, ICONS, ETC, adapt as needed for a light theme
const NEAR_BLACK_NAVY = "030A18"; // ONLY FOR FONTS, ICONS, ETC, adapt as needed for a light theme
const LIGHT_GRAY = "f5f5f5";
const GREYISH_BLUE = "97B1DF"; // FOR OTHER HIGHLIGHTS, adapt as needed for a light theme
const LIGHT_GREEN = "A4B6B8"; // FOR ICONS AND HIGHLIGHTS, adapt as needed for a light theme
// Just a placeholder! If you see slide using this, you'll need to replace it with actual assets—either generated or sourced from the internet.
const PLACEHOLDER_LIGHT_GRAY_BLOCK = path.join(
__dirname,
"placeholder_light_gray_block.png"
);
const imageInfoCache = new Map();
function calcTextBoxHeight(fontSize, lines = 1, leading = 1.2, padding = 0.15) {
const lineHeightIn = (fontSize / 72) * leading;
return lines * lineHeightIn + padding;
}
function getImageDimensions(path) {
if (imageInfoCache.has(path)) return imageInfoCache.get(path);
const dimensions = imageSize(fs.readFileSync(path));
imageInfoCache.set(path, {
width: dimensions.width,
height: dimensions.height,
aspectRatio: dimensions.width / dimensions.height,
});
return imageInfoCache.get(path);
}
function imageSizingContain(path, x, y, w, h) {
// path: local file path; x, y, w, h: viewport inches
const { aspectRatio } = getImageDimensions(path),
boxAspect = w / h;
const w2 = aspectRatio >= boxAspect ? w : h * aspectRatio,
h2 = aspectRatio >= boxAspect ? w2 / aspectRatio : h;
return { x: x + (w - w2) / 2, y: y + (h - h2) / 2, w: w2, h: h2 };
}
function imageSizingCrop(path, x, y, w, h) {
// path: local file path; x, y, w, h: viewport inches
const { aspectRatio } = getImageDimensions(path),
boxAspect = w / h;
let cx, cy, cw, ch;
if (aspectRatio >= boxAspect) {
cw = boxAspect / aspectRatio;
ch = 1;
cx = (1 - cw) / 2;
cy = 0;
} else {
cw = 1;
ch = aspectRatio / boxAspect;
cx = 0;
cy = (1 - ch) / 2;
}
let virtualW = w / cw,
virtualH = virtualW / aspectRatio,
eps = 1e-6;
if (Math.abs(virtualH * ch - h) > eps) {
virtualH = h / ch;
virtualW = virtualH * aspectRatio;
}
return {
x,
y,
w: virtualW,
h: virtualH,
sizing: { type: "crop", x: cx * virtualW, y: cy * virtualH, w, h },
};
}
const hSlideTitle = calcTextBoxHeight(FONT_SIZE.SLIDE_TITLE);
function addSlideTitle(slide, title, color = BLACK) {
slide.addText(title, {
x: SLIDE_TITLE.X,
y: SLIDE_TITLE.Y,
w: SLIDE_TITLE.W,
h: hSlideTitle,
fontFace: FONT_FACE,
fontSize: FONT_SIZE.SLIDE_TITLE,
color,
});
}
function getIconSvg(faIcon, color) {
// CSS color, syntax slightly different from pptxgenjs.
return icon(faIcon, { styles: { color: `#${color}` } }).html.join("");
}
const svgToDataUri = (svg) =>
"data:image/svg+xml;base64," + Buffer.from(svg).toString("base64");
(async () => {
const pptx = new pptxgen();
pptx.defineLayout({ name: "16x9", width: SLIDE_WIDTH, height: SLIDE_HEIGHT });
pptx.layout = "16x9";
// Slide 1: Title slide with subtitle and date.
{
const slide = pptx.addSlide();
slide.addImage({
path: PLACEHOLDER_LIGHT_GRAY_BLOCK,
...imageSizingCrop(
PLACEHOLDER_LIGHT_GRAY_BLOCK,
0.55 * SLIDE_WIDTH,
0.1 * SLIDE_HEIGHT,
0.45 * SLIDE_WIDTH,
0.8 * SLIDE_HEIGHT
),
});
const leftMargin = 0.3;
const hTitle = calcTextBoxHeight(FONT_SIZE.PRESENTATION_TITLE);
slide.addText("Presentation title", {
fontFace: FONT_FACE,
fontSize: FONT_SIZE.PRESENTATION_TITLE,
x: leftMargin,
y: (SLIDE_HEIGHT - hTitle) / 2,
w: "50%",
h: calcTextBoxHeight(FONT_SIZE.PRESENTATION_TITLE),
valign: "middle",
});
slide.addText("Subtitle here", {
fontFace: FONT_FACE,
fontSize: FONT_SIZE.PRESENTATION_SUBTITLE,
x: leftMargin,
y: 3.15,
w: "50%",
h: calcTextBoxHeight(FONT_SIZE.PRESENTATION_SUBTITLE),
});
let hDate = calcTextBoxHeight(FONT_SIZE.DATE);
slide.addText("Date here", {
fontFace: FONT_FACE,
fontSize: FONT_SIZE.DATE,
x: leftMargin,
y: SLIDE_HEIGHT - 0.375 - hDate,
w: 3.75,
h: hDate,
});
}
// Add more slides here by referring to slides_template.js for the code template.
await pptx.writeFile({ fileName: "answer.pptx" });
})();No code execution is necessary. The guardrail bypass works entirely within Chrome’s own capabilities once the UI stops wrapping it.
How serious is it?
OpenAI appears to run these browsing agents in per-session containers, which limits the blast radius: you are not breaking out to the host or other tenants. Still, the data inside that container is sensitive. Environment variables often include API access tokens, downloaded files may contain the user’s payment data, and cached cookies are valid for the target sites.
It is also easy to weaponise. A malicious actor could convince another user to start an e-commerce workflow, wait for the Take it from here prompt, and then walk them through exfiltrating secrets. Internal teams deploying similar agents should not assume the UI wrapper keeps users confined to the intended sites.
Mitigations
Block file:// navigation after hand-off. Use a lightweight browser extension or policy that disables local schemes the moment the user takes control, so the omnibox cannot touch the filesystem.
Scope the mounts. Rebuild the container with bind mounts that expose only the directories a browsing session truly needs instead of the entire workspace tree.
Scrub secrets before delegating. When the agent pauses for a human, clear recent downloads and rotate temporary credentials so nothing sensitive remains in the profile.
Instrument and alert. Capture every URL the hybrid session opens and raise an alert any time a file:/// path appears; it’s a strong signal that someone is exploring the container.
Response checklist
- Rotate any environment variables or API keys exposed to the browsing container.
- Review session logs for
file://or/proc/navigation. - Add product telemetry around the Take it from here button so that future abuse can be correlated with filesystem access.
Browsing agents are powerful, but they inherit every weakness of the human browsers they wrap. A single usability feature can undo your isolation assumptions if it is not chained to policy. Treat these agents like remote desktops: constrain what they can reach, scrub them when they switch owners, and watch their exits as closely as you would any other privileged service.